Vorhersage der Gewinnwahrscheinlichkeit von League-of-Legends-Spielen während der Championauswahl mittels Machine Learning
Diese Arbeit untersucht, wie gut sich die Gewinnwahrscheinlichkeit eines League of Legends Matches bereits in der Championauswahl schätzen lässt. League of Legends ist ein Online Teamspiel, in dem zwei Teams mit je fünf Spielern gegeneinander antreten. Vor Spielbeginn werden Champions ausgewählt und teils gesperrt. Schon in dieser Phase entstehen Vorteile, weil Matchups, Rollenverteilung und die Kombination der Champions bestimmen, wie ein Team Kämpfe startet, Ziele kontrolliert und welche Spielidee am besten funktioniert.
Im Zentrum steht eine realistische Situation aus der Rangliste: Man kennt die eigenen Werte recht gut und sieht die ausgewählten Champions, hat aber zu den neun anderen Spielern kaum verlässliche Informationen. Deshalb wird die Vorhersage aus Sicht eines einzelnen Spielers modelliert. Detaillierte Werte dieser Person dürfen direkt genutzt werden. Für Mitspieler und Gegner fliessen nur Vorwerte ein, die aus historischen Durchschnittswerten abgeleitet werden, zum Beispiel Champion Leistung nach Rangbereich oder typische Erfolgswerte von Matchups. Damit bleibt das Setting nahe an dem, was in der Championauswahl wirklich verfügbar ist.
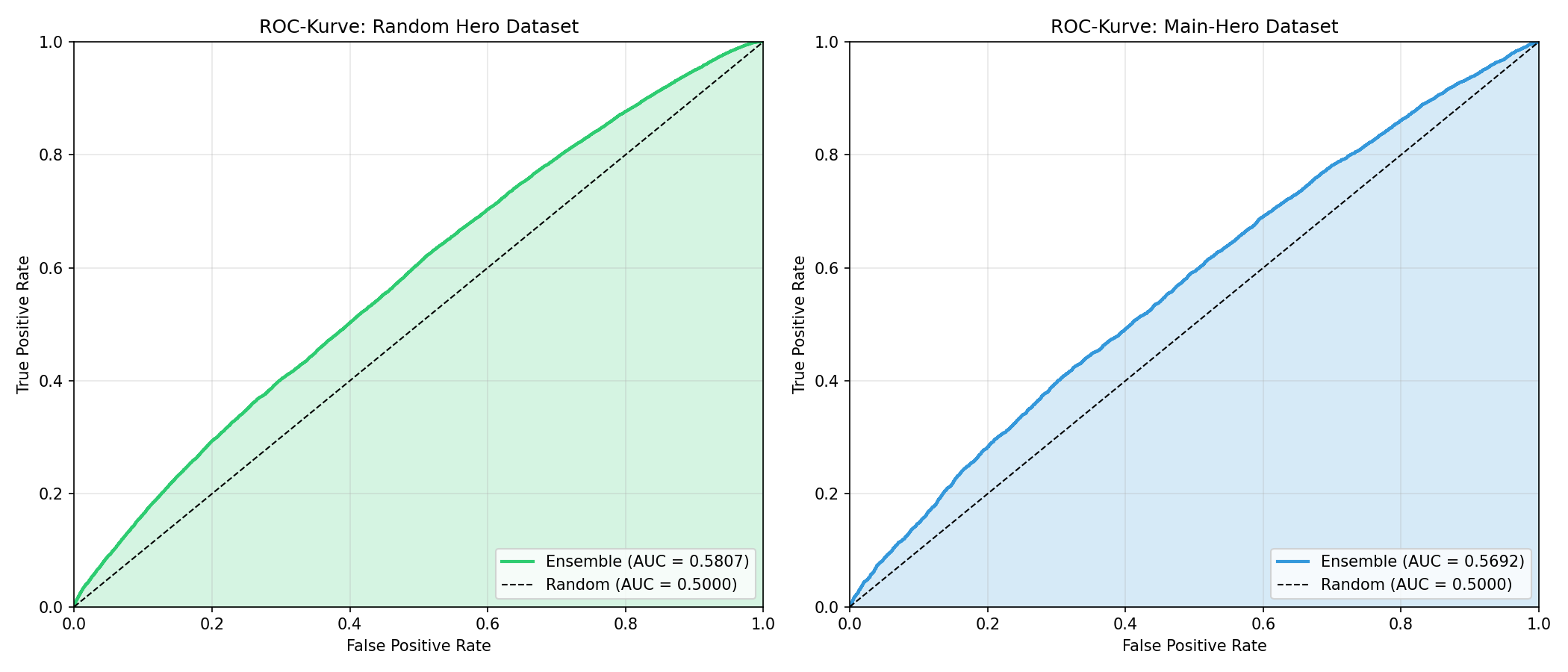
Als Datengrundlage wurden über 320’000 Ranglistenspiele aus zwölf Regionen über die offizielle Riot Games API gesammelt. Zur Evaluation werden zwei Datensätze betrachtet: einmal mit zufällig gewähltem Spieler pro Match und einmal mit einem Spieler, der als Hauptspieler für einen Champion gilt. Aus den Rohdaten wurden Merkmale zur Championauswahl, zu Matchups, zur Spielseite, zum Rang sowie zu persönlichen Vorwerten abgeleitet. Zuerst entstanden 60 Merkmale. Um ein kleines und robustes Merkmalset zu erhalten, wurde eine systematische Ablation Study durchgeführt. Dabei wurden 31’260 Merkmalskombinationen getestet, um jene Merkmale zu finden, die stabil zur Modellleistung beitragen und nicht nur zufällig auf einzelnen Teilmengen gut aussehen. Zusätzlich werden Trainings und Testdaten zeitlich getrennt, damit Trends aus späteren Spielen nicht versehentlich in die Vorwerte einfliessen.
Für die Modellierung werden mehrere Verfahren des maschinellen Lernens kombiniert. Ein wichtiger Baustein ist ein separat trainiertes neuronales Netz im Siamese Aufbau, das aus den Champion Listen beider Teams einen Team Score lernt. Dieser Score fasst die Teamzusammenstellung kompakt zusammen und wird danach als zusätzliches Merkmal in das Hauptmodell übernommen. Das Hauptmodell ist ein gewichtetes Ensemble aus LightGBM, XGBoost und ExtraTrees, sodass unterschiedliche Modelltypen ihre Stärken einbringen und sich Fehler gegenseitig ausgleichen.
Die Ergebnisse zeigen eine moderate, aber klare Vorhersagekraft. Das Ensemble erreicht eine AUC von rund 0.58 und sagt etwa 55 Prozent der Matches korrekt voraus. Die Leistung ist auf beiden Datensätzen ähnlich, was auf eine stabile Generalisierung hindeutet. Besonders einflussreich sind der gelernte Team Score, die persönliche Winrate der betrachteten Person und der Vorteil der blauen Seite. Das Modell liefert Wahrscheinlichkeiten und eignet sich dadurch als Orientierung, nicht als sichere Aussage für einzelne Spiele.
Im Fazit zeigt die Arbeit, dass bereits in der Championauswahl messbare Signale vorhanden sind, selbst unter starken Informationseinschränkungen. Gleichzeitig bleiben die Grenzen deutlich: Ohne genaue Informationen zu den anderen Spielern und ohne Daten aus dem Spielverlauf sind nur moderate Verbesserungen möglich. Praktisch ist der Ansatz vor allem für Analyse, Lernhilfen und Coaching, etwa um Teamideen sichtbar zu machen, Matchups besser einzuordnen und Entscheidungen über viele Spiele hinweg zu verbessern.