Analyse und Vergleich von Methoden zur Erstellung von Deepfakes: Ein Fokus auf Text-to-Image-Prompts und DeepFaceLab


Der rasante Fortschritt in der KI, besonders seit der Einführung von ChatGPT, hat zu neuen Anwendungen geführt, die sowohl im privaten als auch im beruflichen Umfeld breite Anwendung finden. Besonders prägend sind dabei Deepfakes, die durch ihre realitätsnahe Darstellung ethische, aber auch rechtliche Fragen aufwerfen.
Der Begriff Deepfakes setzt sich aus den Wörtern «Deep» aus «Deep Learning» und «Fake» für «Fälschung» zusammen. Dabei beschreibt Deep Learning die Methode, mit deren Hilfe diese Fälschungen erstellt werden.

Über die letzten Jahre hat sich der Begriff etabliert und steht für realistisch wirkende, digitale Fälschungen, die innerhalb von Bild-, Video-, Text- oder Audio-Medien eingesetzt werden.

Ziel/Aufgaben
Deepfakes sind mittlerweile keine Randerscheinung des Internets mehr und begegnen uns immer häufiger. Dabei warnen Experten davor, dass sich insbesondere im Jahr 2024 Deepfakes in einem noch nie dagewesenen Umfang verbreiten können. Allein in diesem Jahr finden in über 60 Ländern demokratische Wahlen statt, wobei knapp 4 Milliarden Menschen ihre Führung wählen. Die Verbreitung von falschen Informationen in Form von Texten, Videos oder Bildern kann dabei zu gesellschaftlichen Implikationen führen.
Die Arbeit soll dabei helfen, wichtige Erkenntnisse in der Forschung im Gebiet der KI zu erlangen, insbesondere im Bereich von Deepfakes. Die Erkenntnisse können dabei als Grundlage dienen, weiterführende Studien in diesem Gebiet zu vollziehen. Die durch die Umfrage gewonnenen Erkenntnisse über die Erkennung von Deepfakes sollen dabei helfen, das öffentliche Bewusstsein für Deepfakes und deren Erkennung zu stärken, aber auch aufzeigen, dass die Erstellung und schliesslich die Verbreitung von Deepfakes im Mainstream angelangt sind.
Methoden
Um die Deepfakes zu erstellen, wurde sich zweier Methoden bedient: Text-to-Image und General Adversarial Networks (GANs).

Text-to-Image
Text-to-Image funktioniert über die Verwendung von Prompts als Anweisung zur Erstellung von Bildern. Dabei wird der eingegebene Prompt von einem LLM (Large Language Model) interpretiert und an eine generative KI zur Erstellung von Bildern weitergegeben. In diesem Experiment wurden für Text-to-Image ChatGPT mit DALL·E und Adobe Photoshop (Beta) verwendet.
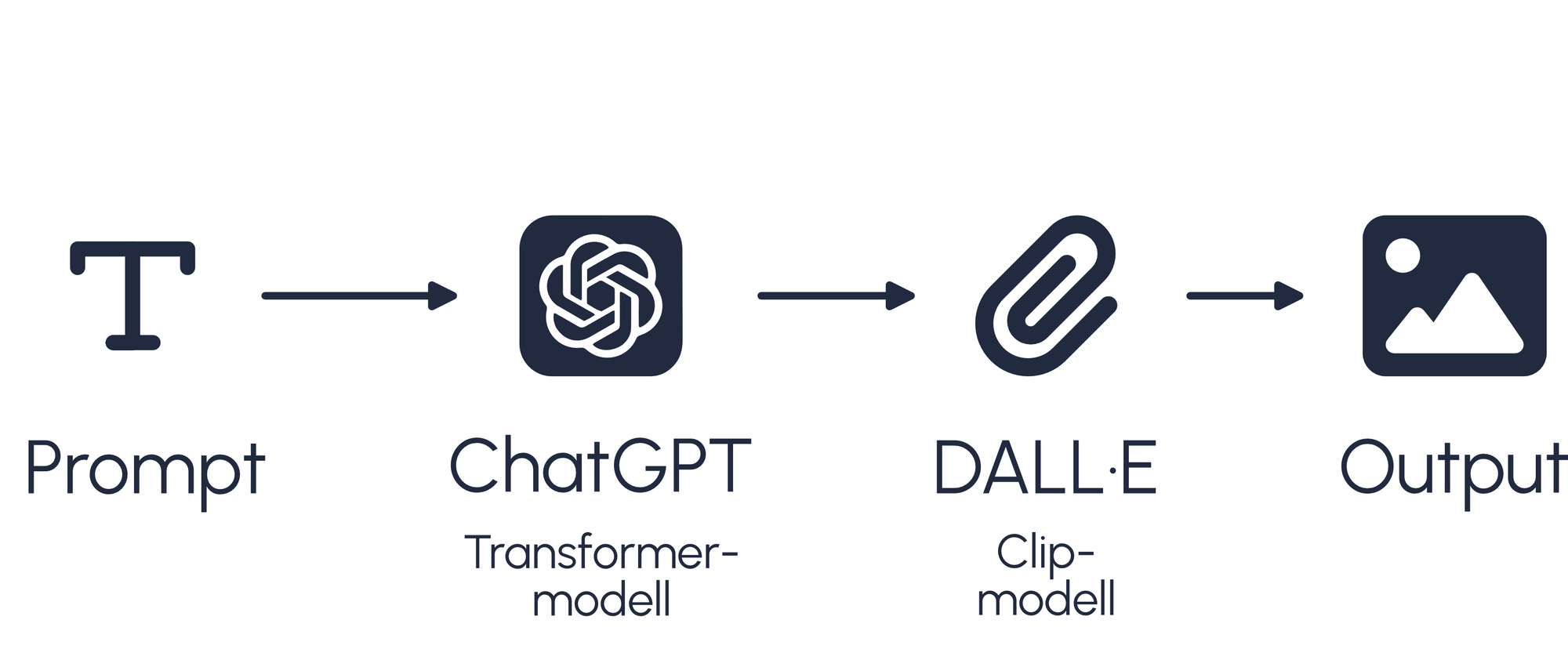
Insbesondere bei ChatGPT mit DALL·E wurden die Bilder anhand eines Prompt-Engineering erstellt. Dabei wurde der Prompt nach jeder Durchführung anhand des Outputs von DALL·E evaluiert und umgestellt. Damit konnte sichergestellt werden, dass das in der Umfrage verwendete Deepfake von möglichst hoher Qualität ist.
Bei der Erstellung der Deepfakes in Adobe Photoshop (Beta) mit Generative Fill hingegen wurde darauf geachtete, dass die Eingriffe in das Bild so klein sind wie möglich. Zudem handelte es sich bei den verwendeten Prompts um einzelne Wörter.
Generative Adversarial Networks (GANs)
Weitere Deepfakes wurden mithilfe von GANs erstellt. Hierbei handelt es sich um neuronale Netzwerke, die in Konkurrenz zueinander stehen. Bei diesen neuronalen Netzwerken handelt es sich einerseits um den Generator, andererseits um den Diskriminator. Der Generator hat die Aufgabe, Bilder zu erstellen. Der Diskriminator hat die Aufgabe, die Bilder zu erkennen. Durch einen Feedback-Loop, ob ein Bild erkannt wurde oder nicht, verbessern sich beide Modelle schrittweise, bis es dem Generator möglich ist, Bilder zu erstellen, die vom Diskriminator nicht mehr von echten Bildern unterschieden werden können.
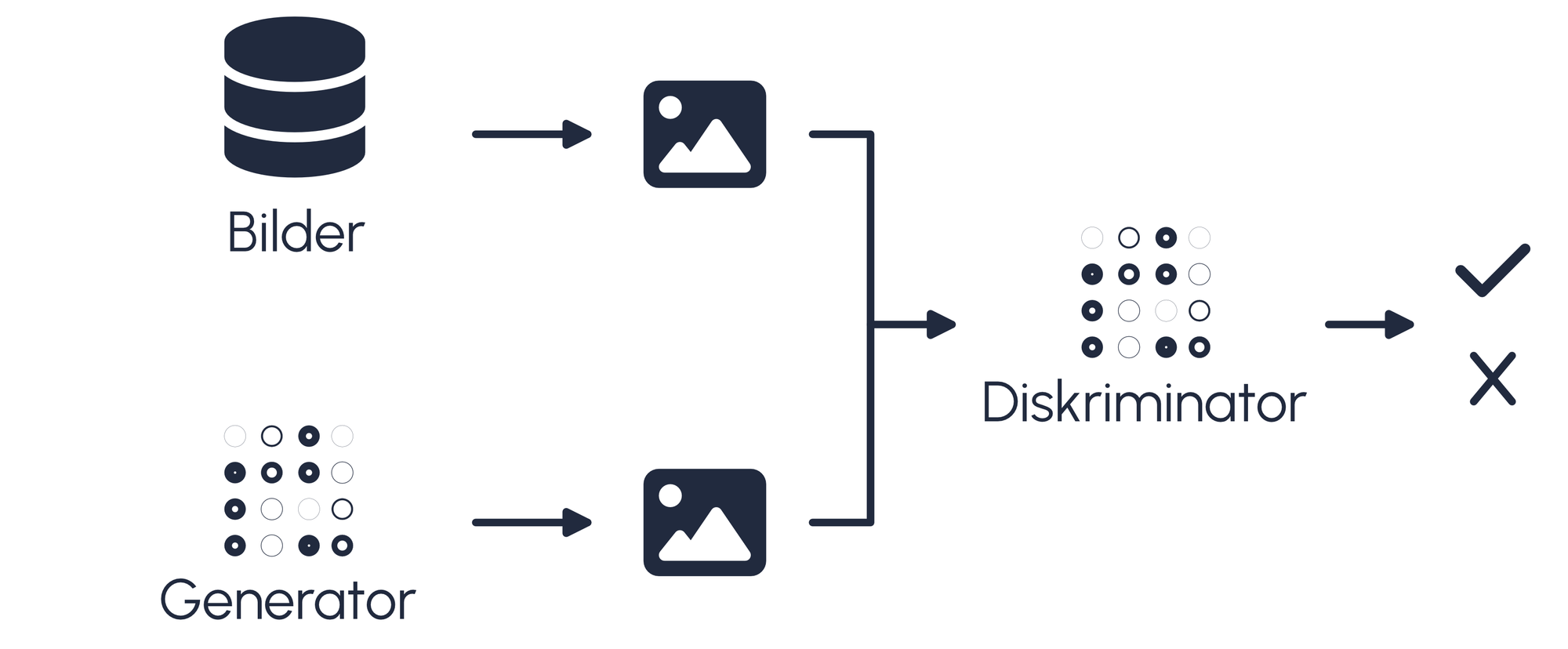
GANs wurden mithilfe der Software 'DeepFaceLab' verwendet und auf dem Server der BFH trainiert. Dabei wurden unter anderem das Dataset selbst zusammengestellt und die Modelle mit diesen Datasets trainiert. Pro Trainingsdurchgang wurden 150'000 Iterationen gemacht, was 150'000 erstellten Bildern entspricht. In regelmässigen Abständen wurde das Training unterbrochen und die Parameter neu eingestellt (Fokus auf Gesichtsmerkmale, Farbe etc.).
Umfrage
Die erstellten Bildern wurden nebst einigen Fragen in einer Umfrage gezeigt. Hierbei ging es darum, herauszufinden, ob es den Teilnehmern möglich ist, die Deepfakes richtig zu klassifizieren. Die Resultate wurden im Anschluss einfach ausgewertet.
Die Umfrage selbst wurde auf Basis der ReactJS-Library SurveyJS erstellt und in einem Hosting auf Vercel veröffentlicht. Mithilfe einer API-Einbindung wurden die Daten in eine Firebase Firestore-Datenbank gespeichert.
Ergebnisse
Die Ergebnisse zeigen, dass insbesondere die Deepfakes, die in ChatGPT mit DALL·E erstellt wurden, nicht von hoher Qualität oder genug realitätsnahe sind. Von insgesamt 96 Teilnehmern wurden diese Deepfakes von einer Person falsch deklariert.
Die Deepfakes, die mithilfe von DeepFaceLab erstellt wurden, wurden von über 60% der Teilnehmenden richtig klassifiziert. Die Fehlerquote betrug hierbei 36%.
Schliesslich wurden die Deepfakes die in Adobe Photoshop (Beta) mit Generative Fill erstellt wurden, am häufigsten falsch deklariert. So wurde das erste Deepfake von 28% der Teilnehmenden korrekt erkannt. Das Originalbild hingegen wurde von 86% richtig erkannt. Das zweite Deepfake wurde von 70% der Teilnehmenden korrekt als Deepfake klassifiziert, wobei das originale Bild von 62% der Teilnehmenden falsch als Deepfake klassifiziert haben.